


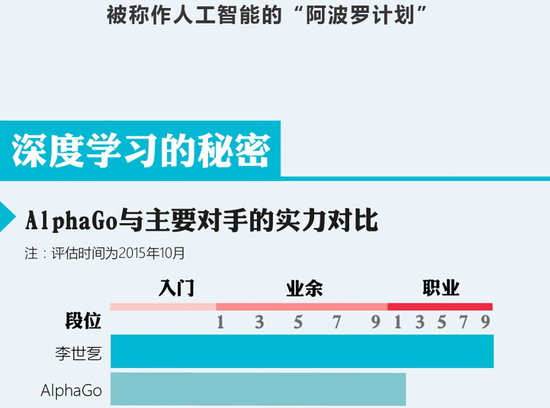
“人机世纪大战”第一局落下帷幕,李世石认输,这是让很多人没有想到的。原本被寄以厚望的李世石,到底为什么会输于古力口中“业余六七段”的Alphago?
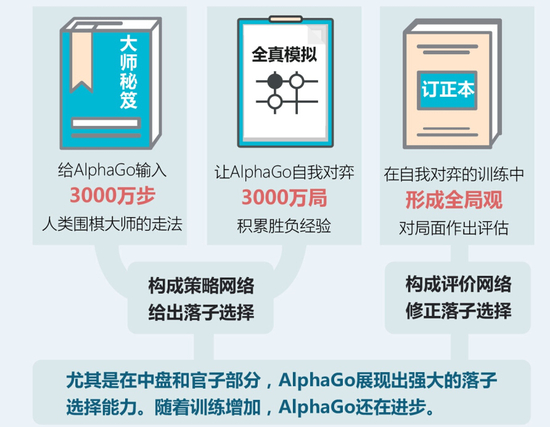
“国际象棋每步大约会出现35种左右的走位可能,而围棋的走位可能则高达250种,每一步250种相乘就意味着整局比赛会出现多到几乎无穷尽的走位方案。”谷歌(微博)DeepMind实验室主管德米斯-哈撒比斯(Demis Hassabis)说道。Alphago在击败欧洲围棋冠军樊麾时学习了3000万盘棋,而经过将近半年的学习,这个数量已经增长到1亿以上。
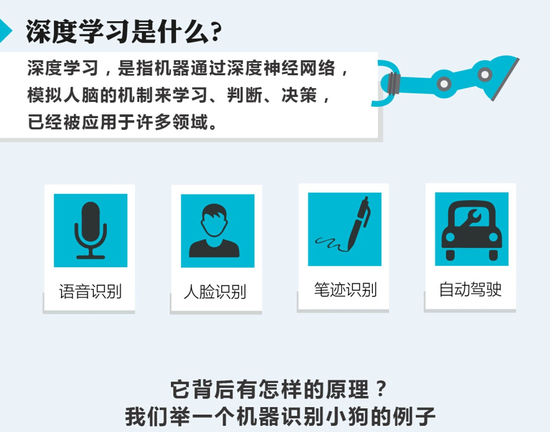
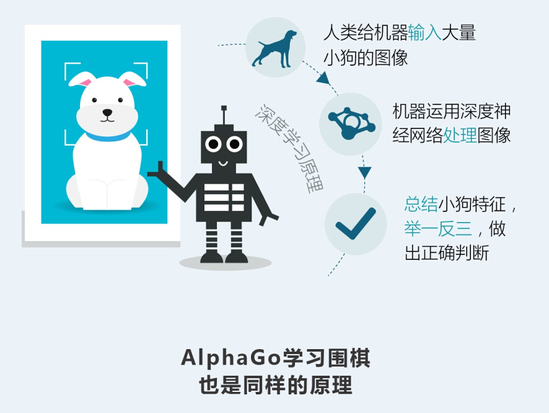
AlphaGo 的核心是两种不同的深度神经网络。“策略网络”(policy network)和 “值网络”(value network)。它们的任务在于合作“挑选”出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里,本质上和人类棋手所做的一样。
其中,“值网络”负责减少搜索的深度——AI会一边推算一边判断局面,局面明显劣势的时候,就直接抛弃某些路线,不用一条道算到黑;而“策略网络”负责减少搜索的宽度——面对眼前的一盘棋,有些棋步是明显不该走的,比如不该随便送子给别人吃。利用蒙特卡洛拟合,将这些信息放入一个概率函数,AI就不用给每一步以同样的重视程度,而可以重点分析那些有戏的棋着。
这意味着Alphago属于典型的力战型棋风,善于敏锐地抓住对手的弱处主动出击,以强大的力量击垮对手。李开复(微博)先生说现在的AlphaGo和1997年击败世界象棋冠军的深蓝相比,从围棋到象棋的难度高了很多,是难度非常大的跳升。
近年来深度学习的技术,非常大的数据量和计算量可以扩张地使用,超过了我们的想象。同时我们也对人所谓的智力,当时有一些错误的幻想,实际上深度学习的成长非常快速,它可以非常好地利用更多地机器。所以在任何客观、科学工程评估的领域,包括游戏,其实是金融、搜索、广告等各方面的应用,人类基本上不会再有更多的机会跟机器来竞争了。
而今天AlphaGo 在战术和策略上的选择证明了这一点,在落后的情况下它也有策略,而不是在心理上打心理战。今天AlphaGo 先出现失误,随后追赶而上,令我们不得不重新去思考机器的学习和优化能力。
Alphago前期的“表现”让李世石轻敌
但是李世石不同,李世石似乎出现情绪上的波动。李世石出生在韩国一个鸟岛上,坚韧不认输,这让他成为愈挫愈勇的棋手。每个棋手都有自己的棋风,今天他占优势之后反而出现失误。这个时候出现戏剧性变化令我们大跌眼镜。
古力认为,李世石在中期时的优势很大,而Alphago则屡屡出现一些很奇怪的下法,犯一些低级错误,这导致了李世石的轻敌,比赛结束时,李世石还剩半个小时左右的时间,而Alphago只剩不到十分钟,这说明李世石没有花很多时间用来思考,这也是他轻敌的一个证据。
不过,轻敌的不只是李世石,古力九段在中期也乐观的表示,Alphago的水平大约在业余六七段左右,优缺点都很明显,但进入后半程后,Alphago的优势显然体现了出来。
CSDN创始人蒋涛在现场表示,Alphago展现出来的实力忽高忽低,导致李世石出现了误判,过于轻敌,导致后期一发不可收拾。据蒋涛介绍,在围棋盘面的局部处理上一直是Alphago的强项所在,现场的古力也表示,Alphago在局部的处理上他也自愧不如。
比赛开始后不久,李开复曾对李世石的走法给了一些建议,“根据大家的分析,李世石在尝试新的打法,这个是非常的不明智,机器人是非常周密的,不要认为棋谱没有出现过的你就去尝试,你没有尝试的东西机器懂得比你多,切忌铤而走险。”对于机器人未来的前景,李开复充满信心,“这次下棋输赢不是最重要的,机器只要达到二段专业水平,打败人类是早晚的事情。”
在前期AlphaGo有重大失误的局面下,李世石求赢不想输。在求稳的心态下出现失误,心理波动很大,下到后来会觉得,即使优势再大最后也会输。很多情况下李世石自己也已经觉得无力翻盘了。
智力消耗、体力消耗、精神压力呈递增趋势,再加上舆论环境等,Alphago可以“两耳不闻窗外事,一心只下好围棋”,但人类是高感知生物,情绪易受到外界环境的干扰。
曾数次击败李世石的柯洁九段就表示“程序强于人类很重要的一点就是不会受情感因素干扰。”机器的水平大概就是冲职业段之前的水平,虽然职业还到不了,但是无限接近于职业了。再加上机器大量的学习和算法,感情上没有波动,这令高级的棋手面对机器时是和以往面对人类对手完全不同。
今天这个局面很多人都没有想到,胜利在望之际,李世石却因为轻敌而输掉比赛。不过经此一役,接下来的四场比赛更值得期待。









 举报
举报